有人可能会有疑问,Heritrix用的好好的,干嘛还要换别的呢?Heritrix固然很好,成熟、稳定、有管理界面、监控、多线程、开箱即用。但这真的适合我们这种垂直爬虫吗?我觉得未必,用Heritrix,你可以通过配置文件来确定接受规则和URL的发现规则,然后直接构建运行就好了。然而对于我来说,它的配置文件中的那些选项说的并不是那么清楚,相关文档也都是很简单的,想用一些复杂的规则都不知道这样对不对,至少要等到好久抓出来东西了,发现多抓了或者少抓了,你才发现配置文件写错了。并且配置文件中的项目也是老多的,这么多东西把人搞的头晕目眩。
好吧,总的来讲,如果你是爬虫老手,对Heritrix的架构了解比较清晰的,Heritrix是个很好的选择。但是对于一个新手,我觉得webmagic更加灵活高效。就拿我的体验来讲,当初用Heritrix抓了3天才抓了七千多数据(可能是我配置文件写的不好),而用webmagic一个白天就抓了一万三的数据。
webmagic介绍
认识webmagic是在知乎上有人推荐,我确定用它使因为该作者比较详细的中文文档(谁让咱英文不太好呢),这是该作者的一个业余项目,但他的代码是非常值得参考的。
官网:WebMagic
可以在我的项目中查看这一部分的代码,这个模块叫做spider。
构架简单介绍
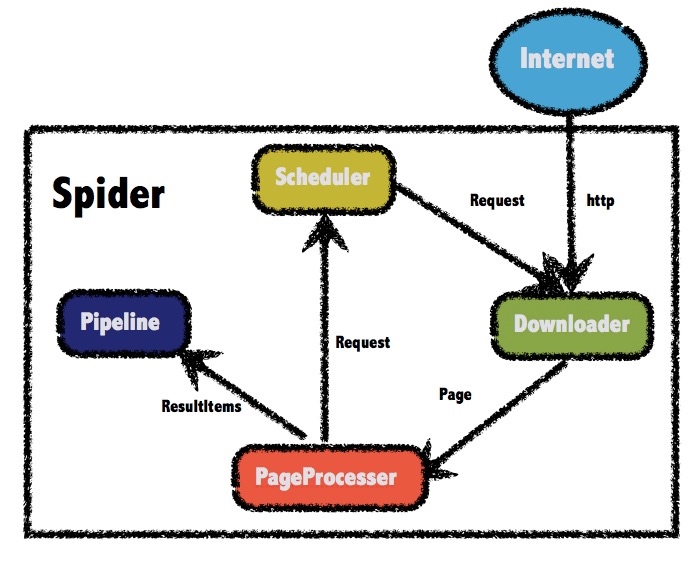
四个组件介绍
Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。 在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。 除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。 Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
构建项目
怎么使用这里也不细讲,文档中说的很清楚。文章中有什么不懂的,可以参考webmagic官方文档,推荐先看完官网文档,并搞懂示例。
引入依赖
我这里用的是gradle来管理工程,所以只要在项目根目录的build.gradle文件中引入需要的依赖,gradle会自动解决相关的一系列依赖,前提是网好 :-) (这里的网好是指能正常使用国际互联网,当然用国内maven镜像也是可以的,但根据我的经验,它总是抽风)。
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.11'
compile "us.codecraft:webmagic-core:0.5.3"
compile "us.codecraft:webmagic-extension:0.5.3"
}
定制页面解析代码
四大组件的说明前面讲过了,对于一般的爬虫来讲,只要定制下PageProcessor就行了,这里也不啰嗦,别的都不讲,就说怎么抓。
正则表达式
对于爬虫最重要一项技能就是正则表达式,关于正则的只是非常多,一时半会也学不完,我也是现学现卖,有了基本的了解之后,后面有什么需要自己查就好了。
我抓取的是去哪儿网的景点页面,一共需要三个正则表达式。先介绍下我要抓取的站点的结构。
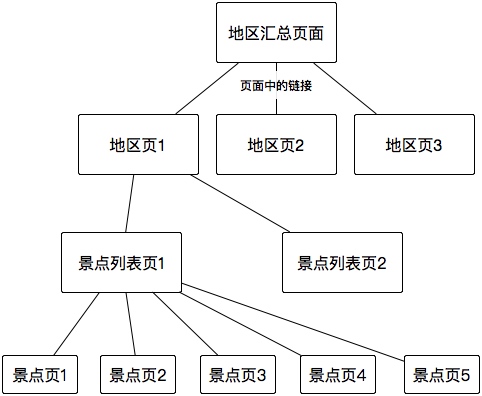
首先我找到了地区的汇总页面,这个汇总页面中有很多地区页的链接,我们要识别出来这些链接,并加入待抓取队列,然后如果抓到了地区页面,要在这个页面中找到这个地区的景点列表页;然后如果抓到了景点列表页,从这个页面我们要找到景点页的链接,并且还有景点列表页的不同页数的链接;最后才是我们需要的景点页,可以对其进行解析或者直接把页面保存下来。前面的所有链接都是帮助找到景点页的帮助页面,而景点页才是真正的目标页面。
注意: 如不特殊说明,本文下面所提到的代码都是Git项目trip-search下的SightSpider/src/main/java/com/fliaping/trip/spider/QunarPageProcessor.java文件中。
我的种子页面是
public static final String URL_SEED = "http://travel.qunar.com/place/";
先来看下正则基础,可以参考这篇文章 正则表达式30分钟入门教程
表1.常用的元字符:
| 代码 | 说明 |
|---|---|
. |
匹配除换行符以外的任意字符 |
\w |
匹配字母或数字或下划线或汉字 |
\s |
匹配任意的空白符 |
\d |
匹配数字 |
\b |
匹配单词的开始或结束 |
^ |
匹配字符串的开始 |
$ |
匹配字符串的结束 |
表2.常用的限定符:
| 代码/语法 | 说明 |
|---|---|
* |
重复零次或更多次 |
+ |
重复一次或更多次 |
? |
重复零次或一次 |
{n} |
重复n次 |
{n,} |
重复n次或更多次 |
{n,m} |
重复n到m次 |
另外,我们可以通过 []来进行字符匹配,例如[aeiou]就匹配任何一个英文元音字母,[0-9]匹配一位范围是0~9的数字。[a-z]匹配所有的小写字母。
注意:如果要匹配真实的 . * ?之类的字符就需要在前面加上转义字符,如 \. \* \?。但是由于有些语言本身的相关转义规则,在写代码的时候可能有些稍微的改动。例如java中需要将 \ 写成 \\,例如匹配一个 . 需要写成 \\. 。
按照前面的分析,我写了如下三个正则表达式:
public final String URL_PLACE = "^http://travel\\.qunar\\.com/p-cs\\d+-[a-z]+$";
//这里的需要匹配的是地区页,像这样的http://travel.qunar.com/p-cs299878-shanghai
public final String URL_SIGHT_LIST = "^http://travel\\.qunar\\.com/p-cs\\d+-[a-z]+-jingdian$";
//这里的需要匹配的是景点列表页,像这样的http://travel.qunar.com/p-cs299878-shanghai-jingdian-1-2
public final String URL_SIGHT = "^http://travel\\.qunar\\.com/p-oi\\d+-[a-z]+$";
//这里的需要匹配的是景点页,像这样的http://travel.qunar.com/p-oi704314-huaihailushangyejie
PageProcessor的实现
webmagic有个注释模式来写爬虫,非常简洁优美,但是这个规则有点复杂,不太适合那样写,最后还是决定用实现PageProcessor的方式来写。
实现PageProcessor最重要的是实现页面处理函数public void process(Page page),在这个函数中我们会对页面进行一些解析,并且将我们需要的链接加入待抓列表中。
例如:
//从种子页得到地区页,分析如果是种子页,则提取地区页链接,加入抓取队列
if (page.getUrl().regex(URL_SEED).match()){
List<String> place_links = page.getHtml().links().regex(URL_PLACE).all();
page.addTargetRequests(place_links);
}
如果是目标页面,对其进行分析,并将需要的信息加入结果中,最后由Pipeline进行输出
else if (page.getUrl().regex(URL_SIGHT).match()){
System.out.println("景点:"+page.getHtml().xpath("//*[@id=\"js_mainleft\"]/div[3]/h1/text()").toString());
//得到景点名字
page.putField("sight_name", page.getHtml().xpath("//*[@id=\"js_mainleft\"]/div[3]/h1/text()").toString());
if(page.getResultItems().get("sight_name") == null){
page.setSkip(true); //跳过这个页面,不进行输出
page.addTargetRequest(page.getUrl().toString());
}
//获取评分
Elements els = page.getHtml().getDocument().getElementsByClass("cur_score");
if( els.size() > 0){
page.putField("sight_score_qunar", els.get(0).text());
}
//获取坐标
page.putField("sight_coordinate", page.getHtml().xpath("//*[@id=\"js_mainright\"]/div/div[2]/div/@latlng").toString());
//获取图片
page.putField("sight_cover", page.getHtml().xpath("//*[@id=\"idNum\"]/li[0]/div[2]/img/@src)").toString());
//将页面输出
page.putField("html",page.getHtml().toString());
}
如果利用jsoup来解析页面中的信息,请参考之前专门讲jsoup的文章。
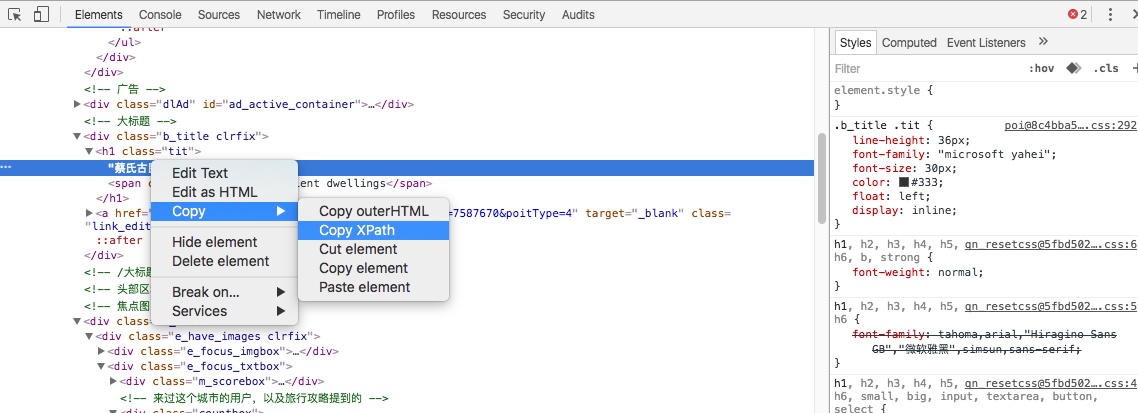
如果用XPath进行元素的选取,可以利用Chrome浏览器的审查元素中的Copy Xpath这个功能。
抓取策略及验证码
因为网站基本都有反爬虫策略,所以我们需要进行一些摸索,知道反爬虫系统的一些脾气,经过测试我设置的是爬取间隔30秒,每次25个线程同时抓取,这样大概20-30分钟会触发一次验证码,因为机器识别验证码的学习成本比较大,我就简单点,每次我手动输入了。
站点的爬取的相关信息设置:
private Site site = Site
.me()
.setDomain("travel.qunar.com")
.setSleepTime(30000)
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36");
如果出现让输入验证码的页面,就自动用浏览器打开这个页面。
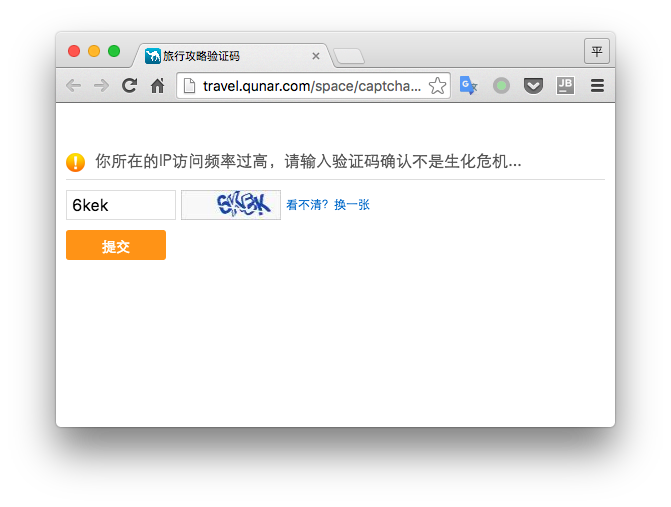
if (page.getHtml().regex("访问频率过高").match()){
//因为是多线程,必须进行同步
synchronized (Main.qunarSpider){
long thisTime = System.currentTimeMillis();
//认证时间超过10秒的才回再次出发验证码,因为有可能刚输完验证码,当前的这个线程刚离开,另外一个阻塞的线程进来再次让输验证码。
if(thisTime-Main.lastVerifyTime > 10000){
Main.qunarSpider.stop();
openUrlInBrower(page.getUrl().toString()); //自己写的函数,在默认浏览器打开这个链接
Scanner scanner = new Scanner(System.in);
scanner.next(); //输入一个字符,手动确认已经填过验证码
Main.lastVerifyTime = System.currentTimeMillis();
Main.qunarSpider.start();
}
page.addTargetRequest(page.getUrl().toString());
}
}
默认浏览器中打开链接
public void openUrlInBrower(String url){
try {
java.net.URI uri = java.net.URI.create(url);
// 获取当前系统桌面扩展
java.awt.Desktop dp = java.awt.Desktop.getDesktop();
// 判断系统桌面是否支持要执行的功能
if (dp.isSupported(java.awt.Desktop.Action.BROWSE)) {
//File file = new File("D:\\aa.txt");
//dp.edit(file);// 编辑文件
dp.browse(uri);// 获取系统默认浏览器打开链接
// dp.open(file);// 用默认方式打开文件
// dp.print(file);// 用打印机打印文件
}
} catch (java.lang.NullPointerException e) {
// 此为uri为空时抛出异常
e.printStackTrace();
} catch (java.io.IOException e) {
// 此为无法获取系统默认浏览器
e.printStackTrace();
}
}
启动抓取
我将结果存在json文件中,因为有些页面的结构有些不同,在抓的时候进行调试不靠谱,所以我把页面保存下来,有问题本地分析比较快。
以下代码片段是SightSpider/src/main/java/com/fliaping/trip/spider/Main.java文件中
qunarSpider = Spider.create(new QunarPageProcessor());
qunarSpider.setScheduler(new FileCacheQueueScheduler("data"))
.addUrl(QunarPageProcessor.URL_SEED)
//.addPipeline(new ConsolePipeline())
.addPipeline(new JsonFilePipeline("data"))
.thread(25)
.run();
运行该文件的 main 函数即可进行抓取。